
Web scraping is a handy tool for gathering information from a website that most developers will use at some point in their life. Web scrapers usually load, parse, and extract useful data from a website's HTML code. However, there are times when this isn't enough, and you might need to take screenshots of a website. For example:
- Debugging: As part of a web crawler or some version of end-to-end testing, you might need to take screenshots of a website to help debug a problem and understand what is being rendered.
- Automating: Automate the routine work of reviewing dashboards or sites for changes and distributing that to other channels like Slack.
- Sharing: Sharing data behind logins with users that don't have access.
- Legal or compliance documentation: Taking screenshots of the contents of a URL as a way of documenting content to provide evidence to legal teams or auditors.
- Tracking changes: Tracking changes to a website and sending out notifications to users.
Elixir is a functional, concurrent, general-purpose programming language mostly used to build scalable and maintainable web applications. In this article, you'll learn several different ways of taking screenshots programmatically with the Elixir programming language, as well as the limitations of each method. You'll also get a better understanding of what is happening behind the scenes when those screenshots are generated.
Prerequisites
For this article, you'll be using Elixir and Node.js for one of the example dependencies. Before we get started, make sure you have the following installed:
- Elixir 11.x or greater
- NPM 8.x or greater
- Node.js 16.x or greater
Please note that it's highly recommended that you use a tool like asdf to install these dependencies.
Taking Screenshots Programmatically
According to Stack Overflow, Elixir has quickly become one of the most-loved languages, and not without reason—it combines powerful language features with Ruby-like syntax. In the context of web scraping, Elixir is a great language to use because of its concurrency and functional features.
However, one important thing to keep in mind is that in order to take screenshots of a website, you need to be able to render the website just like any browser would. The following examples will showcase different libraries and tools that can be used, and the limitations of each.
Using PuppeteerImg
Our first example will be using PuppeteerImg, a library that allows you to take screenshots of websites, to take the screenshots. PuppeteerImg is a wrapper of a Node.js package called puppeteer-img, which is a simple library used to generate screenshots of websites.
The code for this example can be found in this GitHub repo.
Setting Up the Project
Start by creating a new project in your Elixir workspace:
mix new puppeteer_example --supOn success, you'll see the following output:
* creating README.md
* creating .formatter.exs
* creating .gitignore
* creating mix.exs
* creating lib
* creating lib/puppeteer_example.ex
* creating lib/puppeteer_example/application.ex
* creating test
* creating test/test_helper.exs
* creating test/puppeteer_example_test.exs
Your Mix project was created successfully.
You can use "mix" to compile it, test it, and more:
cd puppeteer_example
mix test
Run "mix help" for more commands.Dependencies and Configuration
Next, you'll set up the dependencies and configuration for your project. Go into the puppeteer_example directory, and add the following to the mix.exs file:
defp deps do
[
{:puppeteer_img, "~> 0.1.3"}
]
endProceed to install the dependencies by running the following command:
mix deps.getYou'll also need to install puppeteer-img globally, using the following command:
npm i puppeteer-img -gTaking Screenshots
The next step is to add the main function to your project. Go into the puppeteer_example directory, and add the following to the lib/puppeteer_example.ex file:
defmodule PuppeteerExample do
def take_screenshot(url, filename) do
options = [
type: "jpeg",
path: "./" <> filename
]
case PuppeteerImg.generate_image(url, options) do
{:ok, path} -> IO.puts(path) # where "path" == final path where generated image is stored.
{:error, error} -> IO.puts(error) # where "error" == some error message.
end
end
endOpen up the interactive REPL by running iex -S mix, then run the following command to take a screenshot of the website:
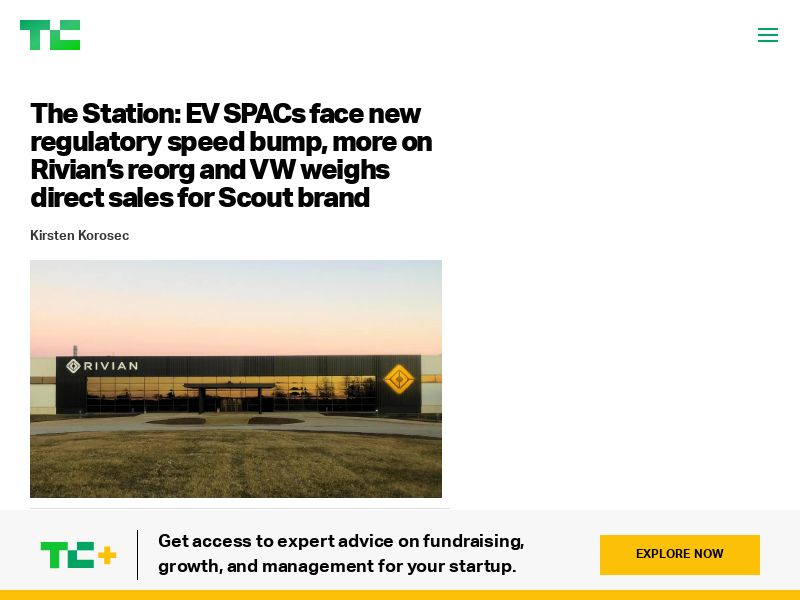
PuppeteerExample.take_screenshot("http://techcrunch.com", "techcrunch.jpeg")If everything worked correctly, you should see the following output:
./techcrunch.jpeg
:okAnd a new screenshot should be generated in the puppeteer_example directory.
Drawbacks and Things to Consider
With very little code, you were able to create an Elixir application that can take screenshots of a website. However, there are a few things to consider with this approach:
- Manual Configuration: We need to configure the library to take screenshots of a website manually.
- Relies on Node.js libraries: PuppeteerImg is a wrapper of a Node.js package, and as such, it requires that Node.js and Puppeteer be installed on the system. This makes deployment and maintenance of the application much more complex, as it requires that you keep track of an additional technology stack. Lack of Automation: PuppeteerImg will work well for instances where you don't need to automate any user action or login to a website, but won't be enough for more complex scenarios. Poor rendering: This approach will also fail to handle and dismiss visual distractions such as popups and cookie banners, and can potentially falter when rendering JavaScript heavy pages.
Using Hound
For more complex scenarios, you can use Hound to take screenshots of a website. Hound is an Elixir library meant for browser automation and writing integration tests. Behind the scenes, Hound supports multiple headless browsers. Notable features include:
- Can support multiple browsers simultaneously.
- Support for Selenium WebDriver, ChromeDriver, and PhantomJS.
- Support for JavaScript-heavy applications, and retry logic.
- Compliant with the WebDriver Wire Protocol.
The code for this example can be found in this GitHub repo.
Setting Up the Project
Start by creating a new project in your Elixir workspace:
mix new hound_example --supOn success, you will see the following output:
* creating README.md
* creating .formatter.exs
* creating .gitignore
* creating mix.exs
* creating lib
* creating lib/hound_example.ex
* creating lib/hound_example/application.ex
* creating test
* creating test/test_helper.exs
* creating test/hound_example_test.exs
Your Mix project was created successfully.
You can use "mix" to compile it, test it, and more:
cd hound_example
mix test
Run "mix help" for more commands.Dependencies and Configuration
Start by adding the dependencies to the mix.exs file:
defp deps do
[
{:hound, "~> 1.0"}
]
endProceed to install the dependencies by running the following command:
mix deps.getUnlike PuppeteerImg, which took care of setting up and launching a headless browser behind the scenes, Hound requires that you do this manually. By default, Hound will use PhantomJS, but you can avoid using another Node.js package by instead using the Selenium WebDriver.
Start by downloading the Selenium standalone server.
Start the server with:
java -jar selenium-server-standalone-3.9.1.jarAlternatively, if you are using macOS with Homebrew, you can install the Selenium standalone server with:
brew install selenium-server-standalone
selenium-server standaloneIn either case, you can confirm that the server is running correctly by visiting localhost:4444/wd/hub to see if you can see the following output:

Finally, you'll need to configure Hound to use the Selenium server. Go into the hound_example directory, and create a new configuration file called config/config.exs:
mkdir config
touch config/config.exsAdd the following to the config/config.exs file:
import Config
config :hound, driver: "selenium", port: 4444Taking Screenshots
With your initial configuration complete, you can now work on the main logic. Go into the hound_example directory, and add the following to the lib/hound_example.ex file:
defmodule HoundExample do
require Logger
use Hound.Helpers
def take_screenshot(url, filename) do
Logger.info "Taking screenshot of #{url} and saving to #{filename}"
Hound.start_session
navigate_to url
take_screenshot("./#{filename}")
Hound.end_session
Logger.info "Screenshot saved to #{filename}"
{:ok, filename}
end
endOpen up the interactive REPL by running iex -S mix, then run the following command to take a screenshot of the website:
HoundExample.take_screenshot("https://techcrunch.com/", "techcrunch_hound.jpeg")If things worked correctly, you should see the following output:
Interactive Elixir (1.13.3) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> HoundExample.take_screenshot("https://techcrunch.com/", "techcrunch_hound.jpeg")
12:40:00.790 [info] Taking screenshot of https://techcrunch.com/ and saving to amgr_hound.jpeg
12:40:05.423 [info] Screenshot saved to techcrunch_hound.jpeg
{:ok, "techcrunch_hound.jpeg"}And should have a screenshot generated in the hound_example directory that looks like this:
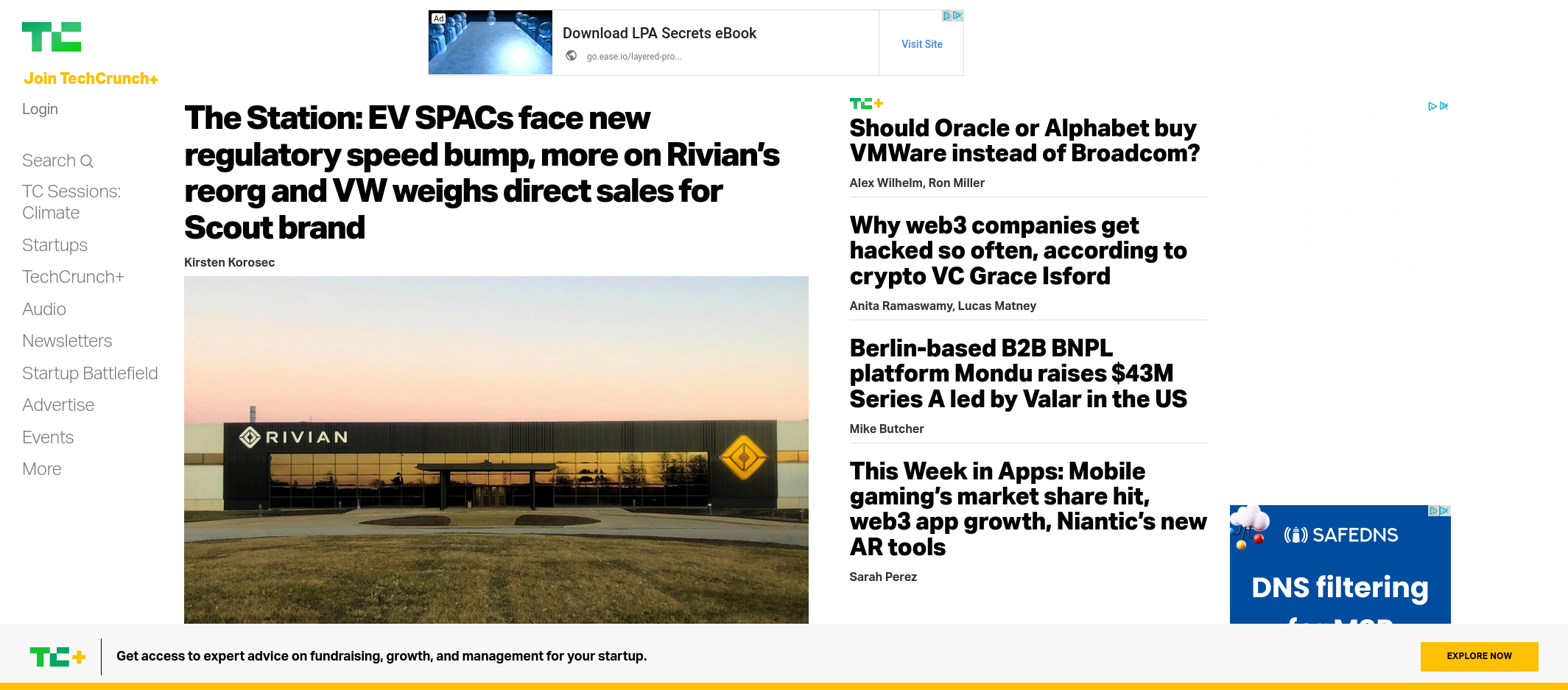
You might have noticed that unlike the previous example, where the screenshot happened without opening a new browser window, in this instance, Hound will open a new browser window for you. The Selenium WebDriver defaults to this when taking a screenshot, although headless mode can be achieved by further tweaking the configuration.
Further configuration options can be found in the Hound documentation.
Drawbacks and Things to Consider
One of the main advantages of using Hound as opposed to PuppeteerImg is that everything happens as part of a session, and you can interact with the page programmatically. This means it can support more complex scenarios, such as:
- Logging in to a website and taking screenshots of a dashboard.
- Interacting with modals and dialogs.
- Following the navigation and taking screenshots of the next page.
However, there are still some drawbacks to this approach:
- Hound is meant to be used for automated testing, so special care must be taken to ensure that errors when trying to access a page are handled gracefully.
- The
take_screenshotmethod is not configurable, and lacks useful options like quality and full-page support. - An application following this approach still depends on a third-party package, though with Selenium, the actual server could be deployed separately from the application.
Using Urlbox
For the final example, you'll leverage Urlbox, a website screenshot service with a simple API. Specifically, this tutorial will use ExURLBox a light wrapper around the Urlbox API.
The code used in this tutorial can be found in this GitHub repo.
Setting Up the Project
Start by creating a new project in your Elixir workspace:
mix new urlbox_example --supOn success, you will see the following output:
* creating README.md
* creating .formatter.exs
* creating .gitignore
* creating mix.exs
* creating lib
* creating lib/urlbox_example.ex
* creating lib/urlbox_example/application.ex
* creating test
* creating test/test_helper.exs
* creating test/urlbox_example_test.exs
Your Mix project was created successfully.
You can use "mix" to compile it, test it, and more:
cd urlbox_example
mix test
Run "mix help" for more commands.Dependencies and Configuration
Start by adding the dependencies to the mix.exs file:
defp deps do
[
{:ex_urlbox, "~> 0.2.0"}
]
endProceed to install the dependencies by running the following command:
mix deps.getTo use Urlbox, you'll need to create an account and get a pair of API credentials. The registration process is straightforward, only asking for an email and password. Once registered, you can retrieve your API credentials directly from the dashboard.
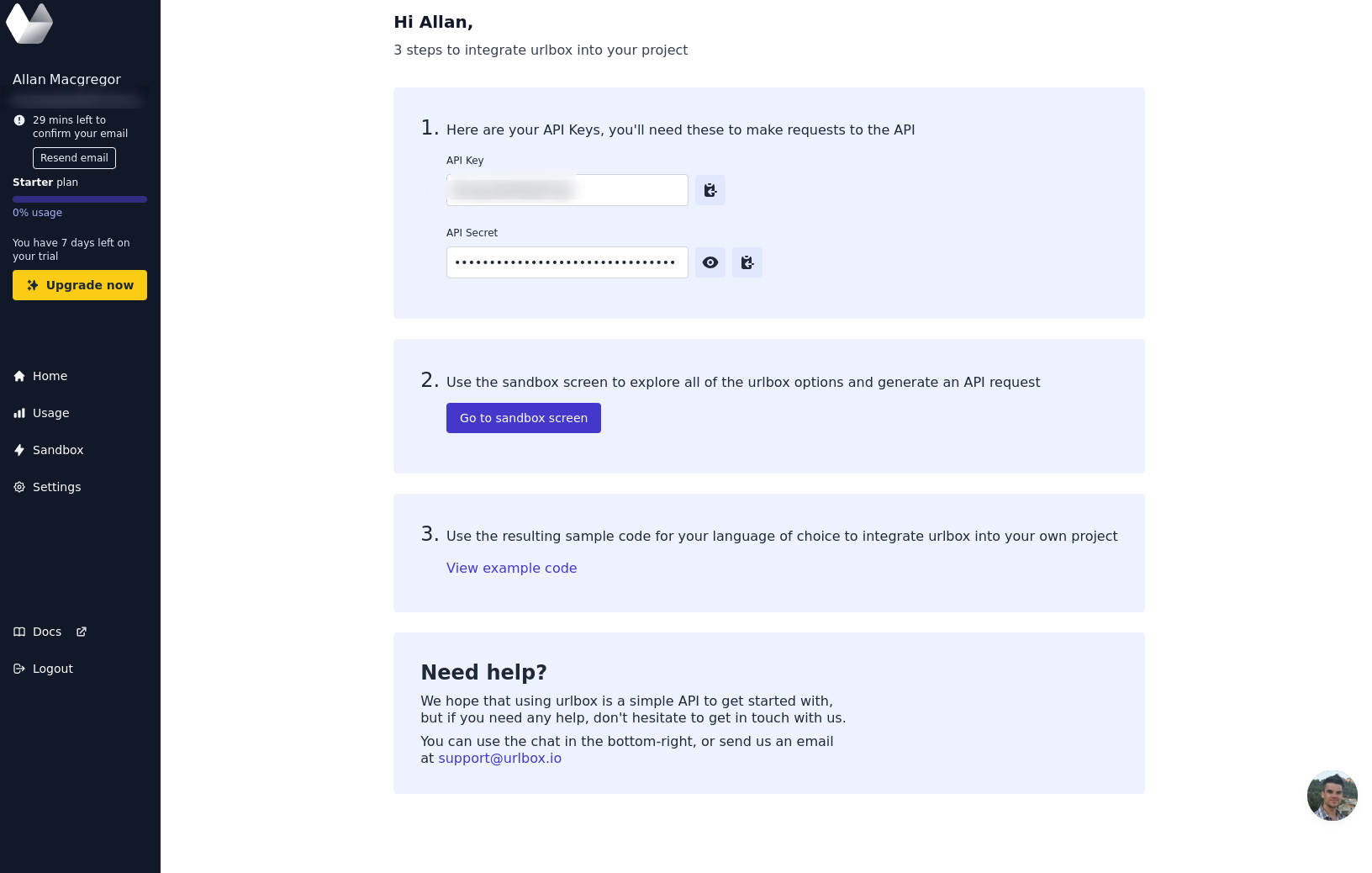
Grab the credentials from the dashboard and add them to the .env file:
URLBOX_API_KEY="YoUrApIKeY"
URLBOX_API_SECRET="YoUrApISeCreT"
Next, you'll have to configure the project to pull the credentials from the .env file. Go into the urlbox_example directory, and create a new configuration file called config/config.exs:
mkdir config
touch config/config.exsAdd the following to the config/config.exs file:
import Config
config :ex_urlbox,
api_key: {:system, "URLBOX_API_KEY"},
api_secret: {:system, "URLBOX_API_SECRET"}This will automatically pull the credentials from the environment variables.
Taking Screenshots
Next, you'll add the main logic to the lib/urlbox_example.ex file:
defmodule UrlboxExample do
@moduledoc """
Documentation for `UrlboxExample`.
"""
def take_screenshot(url, options \\ [format: "png"]) do
{:ok, screenshot} = ExUrlbox.get(url, options)
screenshot.url
end
endThen you can open your REPL and run the following command to take a screenshot of the website:
UrlboxExample.take_screenshot("https://techcrunch.com/")Unlike previous examples, this time around, we go add a Urlbox url to our screenshot, like https://api.urlbox.io/v1/S6vqoSXoPaKZCVjd/0d1a4c912dc683784022d993a5fc45c1c73a2062/png?url=https%3A%2F%2Ftechcrunch.com%2F
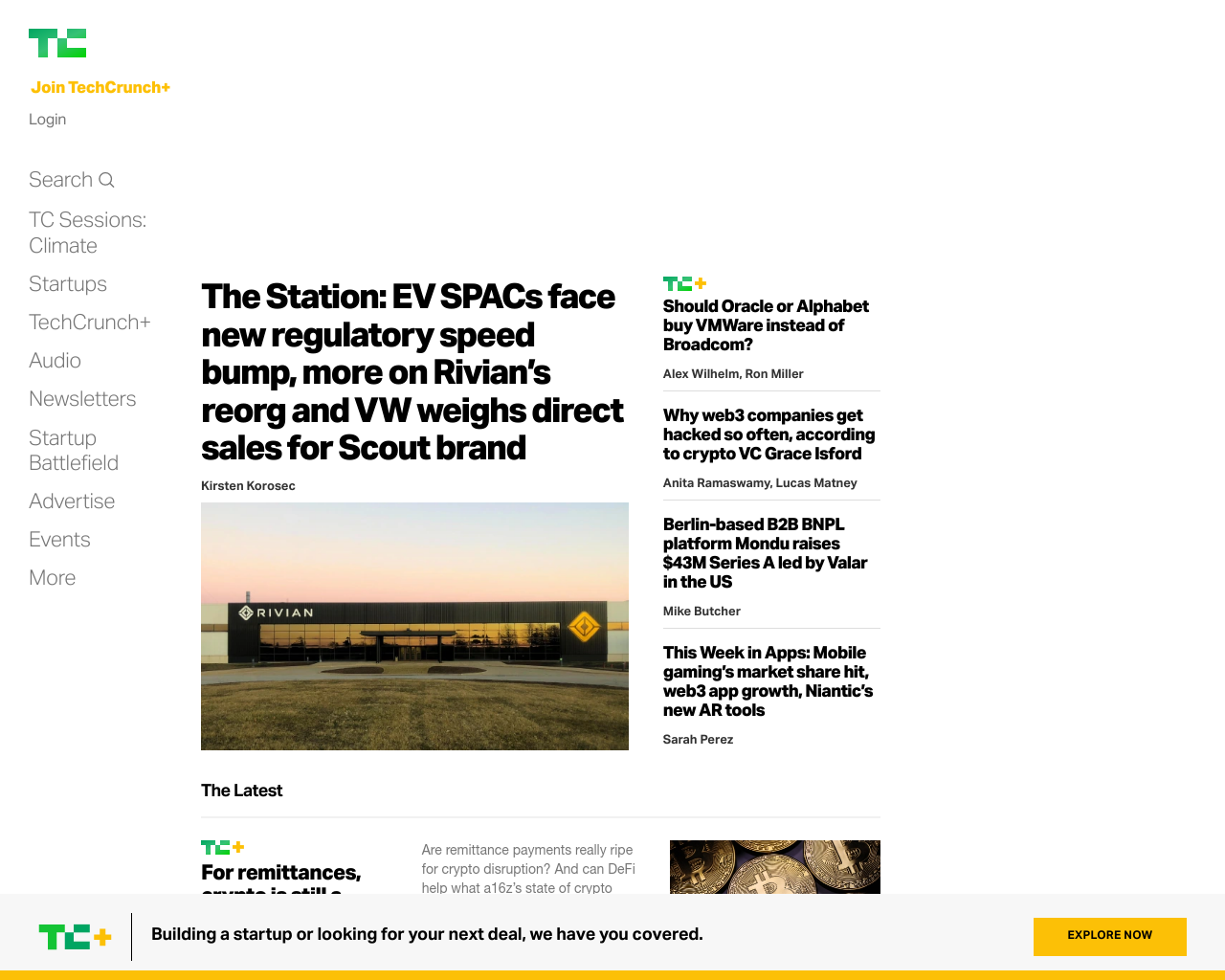
Urlbox is doing all the heavy lifting for us, even storing the resulting screenshot. But this is not all we can do with Urlbox, as it provides some advanced features that go beyond just taking a screenshot.
Let's try some of them out by running the following command:
UrlboxExample.take_screenshot("https://www.geeksforgeeks.org/", [format: "pdf", full_page: true, timeout: 100000])For this request, we added a few additional options:
- format: Instead of saving our screenshot as a JPEG or PNG, we are saving the results of the scrapper as a PDF.
- full_page: This instructs Urlbox to render the full page from header to footer.
- timeout: This increases the time that Urlbox will wait for the page to finish rendering before timing out.
This results in a full-page PDF generated with the contents of the page.
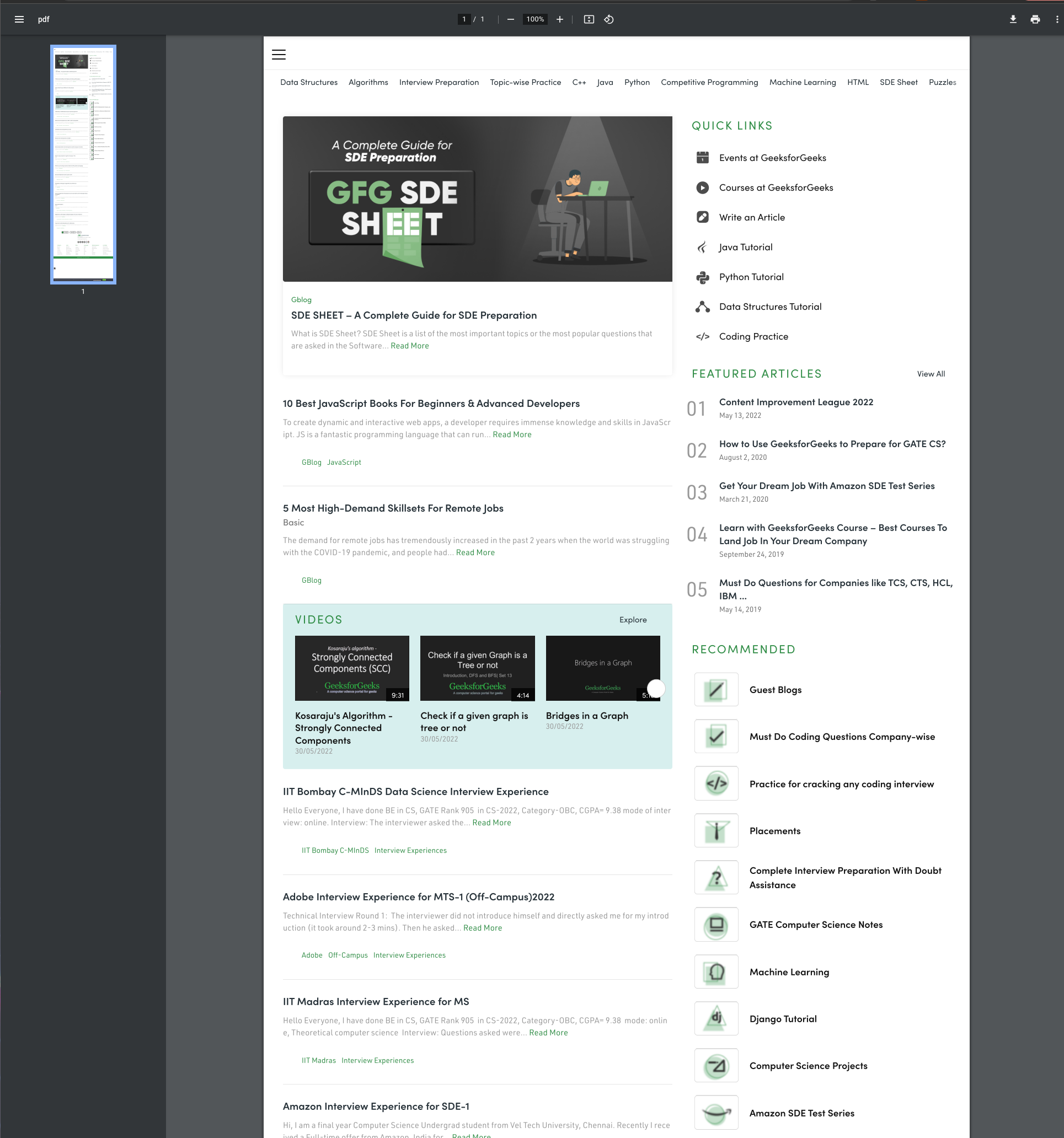
This kind of flexibility and power opens many different use cases, from the ones covered at the beginning of the article to potential uses in ad-tech to generate advertising assets by converting websites and spreadsheets to sharable PDFs.
Conclusion
In this article, you've learned about three distinct ways of taking screenshots with Elixir, from PuppeteerImg, the most limited approach, to a much more flexible approach using Urlbox.
You've also covered the drawbacks and considerations for the main approaches, and how relying on tools like Puppeteer and Selenium will require special care when deploying your application to production.
